最近刷推特时,发现使用 GPT-4o 生成图像的帖子铺天盖地。我原本以为这个功能早就上线了,怎么这两天全网都在晒 GPT-4o 的杰作?仔细一查才恍然大悟:原来是 GPT-4o 刚刚更新,新增了原生图像生成能力,用户可以直接在对话中创建和编辑图片。
OpenAI 的多模态模型 GPT-4o 在 2025 年 3 月 25 日迎来了一次重大革新,尤其是在图像生成方面实现了质的飞跃。这次更新通过官方直播正式发布,标志着 GPT-4o 从单纯的多模态处理迈向原生图像生成的新阶段。以下从更新背景、核心功能、用户反馈与潜在影响等方面进行深度解析。
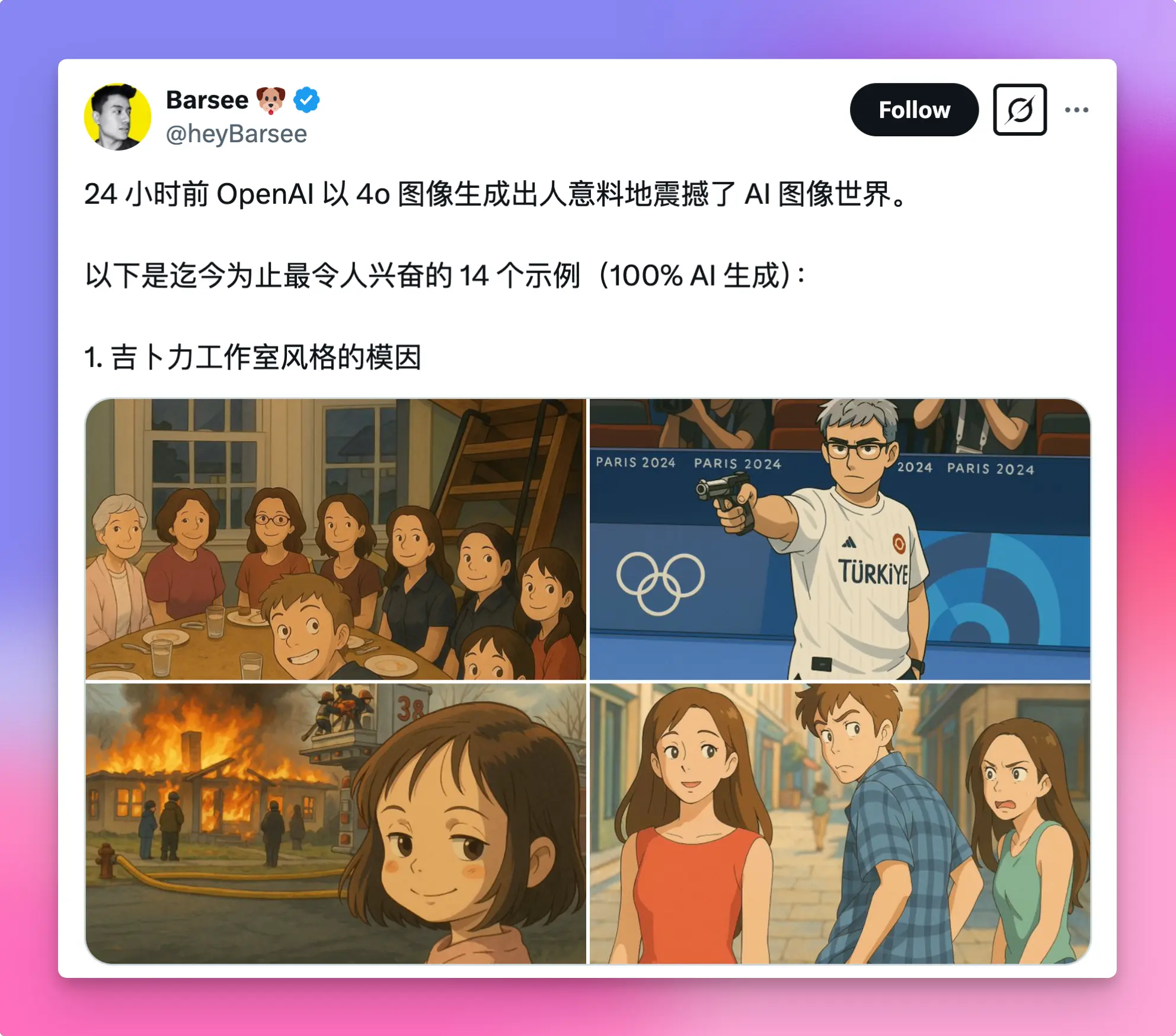
不得不说,生成的图片质量相当出色。以往需要专业设计师耗费大量精力才能输出的图像、图标、海报等,如今 GPT 几秒钟就能搞定。以下是推特上一些大V分享的 GPT-4o 生成作品集锦,供大家欣赏和启发。

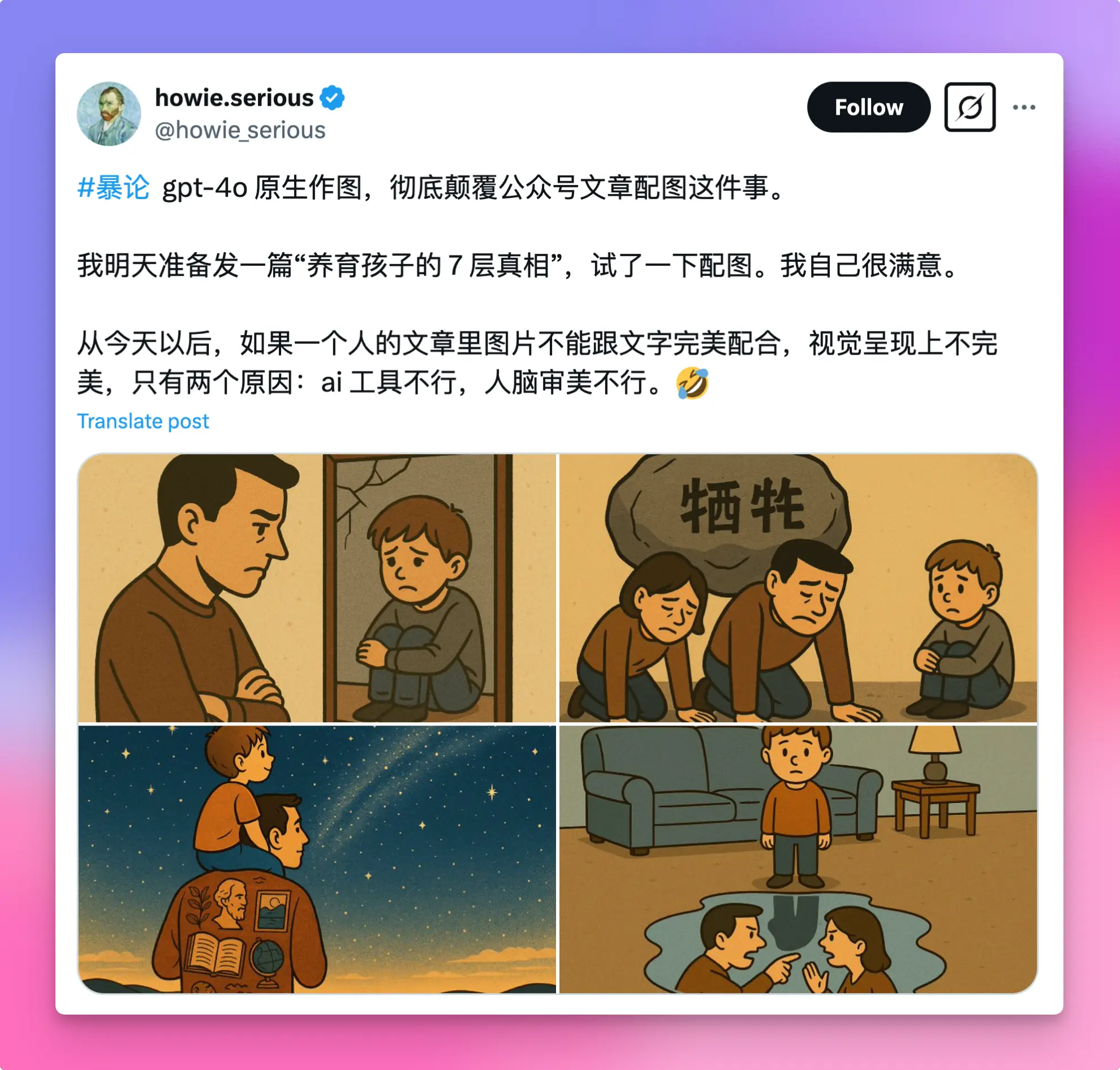
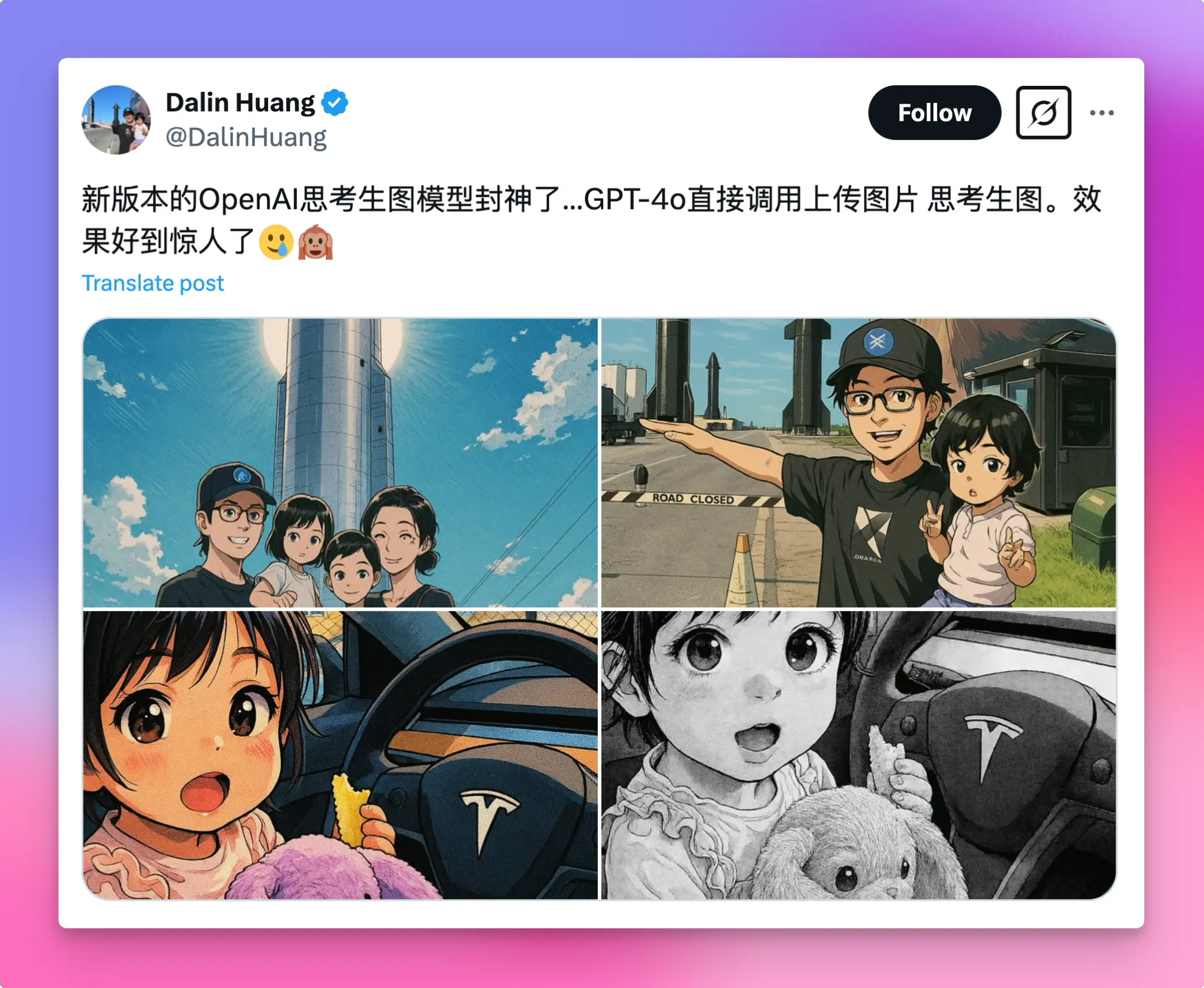
GPT-4o 的前世今生与现有能力
GPT-4o 作为 OpenAI 于 2024 年 5 月推出的旗舰级多模态模型,支持文本、音频和图像的多维输入输出。此前,虽然它可以理解图像内容(比如从视觉信息中抓取关键词),但 图像生成 却一直依赖另一个独立模型 DALL-E 3。DALL-E 3 虽然也集成在 ChatGPT 里,但与 GPT-4o 的文本处理完全是两套系统,导致上下文割裂,使用体验不够顺畅。
核心更新:原生图像生成来了
2025 年 3 月 25 日,OpenAI 正式宣布 GPT-4o 已具备原生图像生成与编辑能力。这意味着用户无需切换任何第三方工具,仅需在同一个聊天窗口内,就能直接生成并修改图像。据官方透露,该功能已向 ChatGPT 的 Pro 计划用户(月费 200 美元,但 Plus 用户目前也已完成覆盖)开放,后续将逐步扩展到 Plus 层、免费用户以及 API 开发者。
据 TechCrunch 报道,这次升级比 DALL-E 3 更加精准。GPT-4o 在生成图像时会进行更长时间的“思考”以优化细节与准确性——例如,它能够更出色地渲染文字,处理复杂场景,并保证多步指令前后响应的一致性。
用户反馈与成果展示
更新发布后,全球用户(尤其中文用户)纷纷在 X 上晒出自己的新成果。比如用户 @_cyberkittyy 分享了一组用 GPT-4o 制作的“动漫 × Nike 概念”图像,并直呼“简直炸裂”。

图像生成提示词与实操
以下提示词灵感来自推特大佬 @hylarucoder,同时配有示例图像。如果觉得有帮助,别忘了去关注这位大佬以示支持。此处仅作学习展示(侵删)。
1:「帮我生成一张庆祝推特 10000 粉丝的设计图」

2:「幽默搞笑风,最好有个紫色头发日漫妹子说「我还有523个粉丝才毕业,请求订阅」

3:「我想要这张图片的风格,但是内容变更为「三个紫毛妹妹」第一个举牌子「点赞」第二个举牌子「关注」第三个举牌子「收藏」,动作各异。照片要宽一些,能容下三个人」

4:「Q 一点的版本」

5:「设计一些排版干净简单的封面,你可以直接上传参考图」

原贴中还有更多实用的提示词,感兴趣的朋友可以前去大佬的主页翻阅。
技术细节与横向对比
与 DALL-E 3 不同,GPT-4o 的图像生成基于其自身的多模态训练体系,可以直接利用聊天上下文生成相关性更高的配图。VentureBeat 的报道指出,新功能下生成的图像更逼真,文字渲染也更加准确,面对包含 15 到 20 个对象的复杂提示词都能游刃有余——这正是 DALL-E 3 的短板,后者在多对象场景中非常容易“犯迷糊”。
不过,生成时间可能稍长,部分复杂图像甚至需要一分钟左右。这或许是系统在资源分配与高峰期需求之间做出的权衡。根据 TechRadar 文章的说法,免费用户每天能够生成的图片数量与使用 DALL-E 3 时大致相同,但具体上限可能会根据实际需求动态调整。
潜在应用场景与影响力
这次更新让 GPT-4o 的应用版图进一步扩展:
| 领域 | 应用示例 |
|---|---|
| 艺术与设计 | 快速绘制初稿、成品艺术品或设计素材 |
| 教育 | 制作教学图表与视觉辅助工具 |
| 商业 | 快速生成产品配图或营销素材 |
| 日常生活 | 制作社交媒体图片、活动邀请函等 |
研究表明,这一新功能可能彻底改变 AI 在内容创作领域的角色,尤其在教育和商业领域潜力巨大。不过,伦理风险同样不容忽视:既存在生成不当内容的风险,也涉及版权争议。Maginative 的文章提到,OpenAI 已借助内部机制限制有害内容的生成,但多语言文字渲染(比如非拉丁字母的支持)依然需要持续关注。
局限性及现实挑战
尽管相比以前有了质的飞跃,GPT-4o 的图像生成仍面临一些难题:
| 问题 | 描述 |
|---|---|
| 生成速度 | 比纯文本生成慢,可能影响实时交互体验 |
| 输出精度 | 面对复杂或含糊的提示词,仍有可能翻车 |
| 伦理隐忧 | 可能产出有害内容,版权争议难以根除 |
| 多语言表现 | 非拉丁字符的渲染仍有待优化 |
结语
GPT-4o 原生图像生成功能的登场,称得上是 AI 技术演进中一个重要的里程碑。它大幅增强了模型的多模态能力,尤其在图像生成与文本处理的深度融合上迈出了一大步。这次更新不仅优化了普通用户的使用体验,更为艺术创意、教育培训、商业推广等领域提供了全新的生产力工具。尽管生成速度和伦理风险仍有待攻克,但随着后续迭代,其性能无疑会越来越强大。从全球范围(尤其是中文社区)的热情反馈来看,这项技术的未来影响值得所有人期待。