原本我也盘算着偷个懒,让 AI 代笔写下这篇教程的开头。但试了几回,发现那种“千篇一律的完美开场白”实在用不下去——一眼就能嗅出 AI 的味道,那种人情味和亲身实践的体验感瞬间消失殆尽。
既然这篇内容讲的是“自建 AI 模型”,那还不如老老实实自己动笔,顺便聊聊我为什么决心在服务器上搭一个专属 AI 助手,以及整个搭建过程到底有多简单。
一、为什么需要自建 AI?
如今几乎人人都在借助 AI 完成各种任务:撰写文案、编写代码、查阅资料、总结报告……
我自己在写博客、折腾 VPS 的时候,也时常把问题抛给 AI 处理。
但有几个点,始终让我有些顾虑:
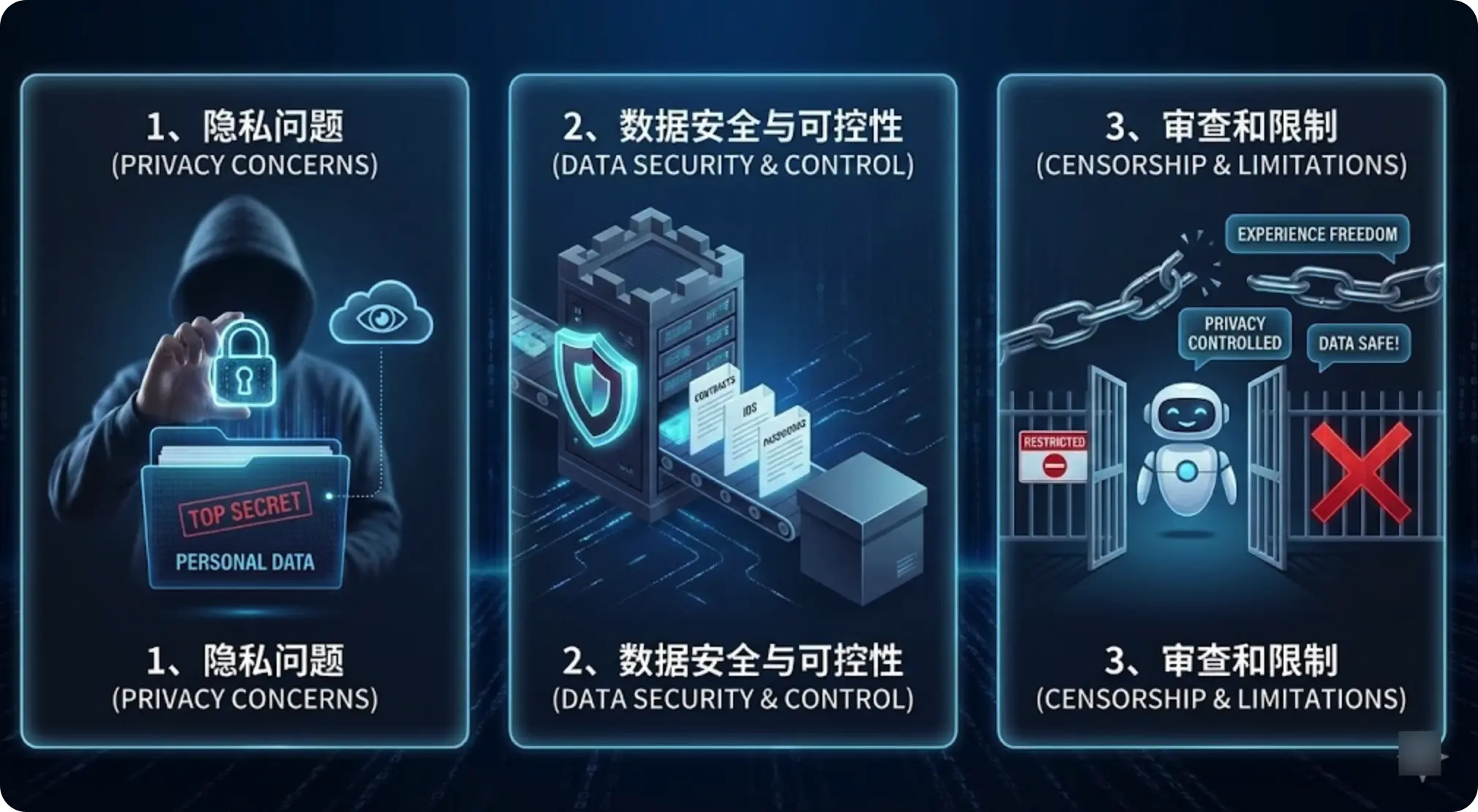
1、隐私问题
公开在网上发布的内容,用在线 AI 处理当然毫无问题。但一旦涉及以下内容,我基本不会使用云端 AI:
- 合同条款、公司内部文档
- 身份证、护照等个人敏感信息
- 带有账号密码、服务器信息的配置文件
无论服务商如何承诺“严格保护用户隐私”,从技术层面看,它们完全有能力访问你输入的数据,更不用说这些数据未来是否会被用于训练下一代模型。
2、数据安全与可控性
很多大模型服务都明确声明:你在产品中输入的内容,可能被用于优化模型。
对普通闲聊而言影响不大,但如果是你的业务逻辑、数据结构、客户信息,被拿去训练模型,心里难免会觉得不安。
3、审查与限制
公有云上的 AI 通常附带严格的内容审核机制。很多时候你只是想了解一些“边缘但不违法”的知识,比如:
- 一些医学、隐私相关的话题
- 某些网络安全的原理性内容
许多国内 AI 会直接回应“作为一个 AI 语言模型,我不能……”,顺便附带一堂道德课。
自建模型的好处在于:你可以自行定义边界。模型本身或许仍有基础安全限制,但整体上不再受平台风控和审查策略的影响——当然,这也意味着你要对自己使用的后果负责。
综上所述,自建 AI 的核心原因可以归纳为三点:
体验更自由、隐私可控、数据安全!
二、自建 AI 模型对电脑或服务器配置有什么要求
要在自己的电脑或服务器上流畅运行 AI 模型,硬件配置不能太寒酸。如果你想在个人电脑上部署,我建议至少配备一块说得过去的显卡,因为如果配置太低,AI 生成内容会慢得让人着急,有时几秒钟才能挤出一个字。
这里给出一些基础建议:
1. 在本地电脑上运行(Windows / macOS)
Windows 建议:
- 显卡:建议至少 GTX 960 / GTX 1060 这一级别及以上
- 内存:16GB 起步更舒适
- 硬盘:预留几十 GB 空间给模型
如果显卡太老、显存太小,模型也不是不能跑,只是输出速度可能会慢到让你怀疑人生。
macOS 建议:
- 芯片:Apple Silicon(M 系列)
- 内存:16GB 比 8GB 更稳妥,尤其是你要跑 8B 模型的话
- 同样需要准备几十 GB 硬盘空间
M 系列的 NPU / GPU 对这类任务相当友好,日常体验比很多老台式机要好。
2. 在 VPS / 服务器上运行(无 GPU 场景)
如果你不想占用自己电脑的资源,在云服务器上部署 AI模型 是个很不错的方案。
以我自己的例子:
我用的是 netcup 的 RS 1000 G12,配置是:
- 4 核 CPU
- 8GB 内存
- 256GB SSD
最低推荐配置(无 GPU):
- CPU:4 核起步(2 核也能跑,但体验较差)
- 内存:8GB 更合适,4GB 只能跑非常小的模型
- 硬盘:至少预留 20–50GB 空间给模型(多个模型时需更多)
三、自建 AI 模型之前需要了解什么
起初我以为“自建 AI 模型”是一件极其繁琐的事。直到我查阅了大量资料并实际操作后才发现,整个过程其实特别简单,本质上就像在电脑或手机上多装了一个稍吃配置的软件。你需要做的事情大致如下:
- 安装一个叫 Ollama 的“模型管理器”
- 用几条命令下载你想要的模型
- 通过命令行或 Web 界面连接上去聊天
整个流程比想象中简单得多,大概也就是三五条命令的事。
四、Ollama 是什么?为什么选择它?

关于 ollama!它是启动大型语言模型(如 GPT-OSS、Gemma 3、DeepSeek-R1、Qwen3 等)最简单的方式。它就像一个手机应用商店,你需要的各种模型都能通过它下载使用。
ollama 支持 Windows、macOS 以及 Linux 三大平台。
Ollama 官方主页:https://ollama.com
Ollama 下载:https://ollama.com/download
Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/
五、热门自建 AI 模型都有哪些?

你可以在 模型 页面找到当前 Ollama 支持的所有 AI 模型。该页面会实时显示最新支持的模型、更新时间以及下载热度。可以看出目前 Deepseek 的下载量依然非常巨大。
以下表格整理了截至博客发布时比较热门的 AI 模型:
| 公司 / 机构 | 代表模型(开源/开放权重) | 简要定位 |
|---|
| Meta(Facebook) | Llama 3.1 / Llama 3.3 / Llama 4 | 全球影响力最大的开源通用模型生态;性能稳定、社区活跃。 |
| 阿里巴巴 / 通义(Qwen) | Qwen3、Qwen2.5、Qwen3-VL、Qwen-Coder | 中文表现优异,全能型;多模态和代码能力突出。 |
| DeepSeek | DeepSeek-R1、DeepSeek-V3、DeepSeek-Coder | 高推理能力,性价比极高;国内外均很受欢迎。 |
| Mistral AI(欧洲) | Mistral Large、Mistral Small、Mixtral | 轻量高效、性能稳定,适合企业级应用。 |
| 微软(Microsoft) | Phi-4、Phi-4-mini、Phi 系列 | 小模型天花板;适合本地部署、边缘设备。 |
| Google / Google DeepMind | Gemma2、Gemma3、Gemma-Vision、Embedding Gemma | 高效易用,单卡可跑;多模态能力强。 |
| 智谱 AI(ZhipuAI) | GLM-4 / GLM-4.6 | 中文场景下表现优秀,推理与对话能力均衡。 |
| OpenAI(开放权重) | GPT-OSS、GPT-OSS-Safeguard | 面向开发者的开放权重模型,偏向推理与工具调用。 |
关于模型中的 b 代表什么意思
不知道你有没有注意到,每个模型的参数后面都带着类似 2b、3b、4b、8b 这样的标识,你知道这些代表什么吗?简单来说,数字后面的 b 代表 “Billion”(十亿),指的是模型中参数(Parameters)的数量。

你可以把“参数”想象成大脑中的“神经元”连接。
- 0.6b = 6 亿参数(相当于极其精简的“迷你脑”)
- 8b = 80 亿参数(标准的“笔记本电脑级”模型)
- 235b = 2350 亿参数(超级巨无霸,相当于服务器集群级的“超级脑”)
对于你的 VPS(无 GPU,纯 CPU)来说,这个数字直接决定了三个关键指标:智力、内存占用、运行速度。
| 尾缀 (参数量) | 智力 / 逻辑能力 | 所需内存 (RAM) | CPU 运行速度 | 适用场景 |
| 0.6b / 1.7b | 低(甚至有点笨) | 极低 (1-2 GB) | 飞快(每秒几十个字) | 简单的翻译、分类,或配置极低的设备。 |
| 4b | 中等 | 低 (3-4 GB) | 流畅(每秒 5-10 字) | 你的 VPS 最佳选择。日常对话、简单问答。 |
| 8b | 良好(主流水平) | 中 (6-8 GB) | 慢(每秒 1-3 字) | 你刚才试过的就是这个。在纯 CPU 上比较吃力。 |
| 14b / 32b | 非常强 | 高 (10-24 GB) | 龟速(不可用) | 需要高端显卡。 |
| 235b | 顶尖(GPT-4 级别) | 巨高 (140GB+) | 无法运行 | 除非你的 VPS 有 200GB 以上内存,否则跑不起来。 |
在一般家用电脑或配置不错的 VPS 上,通常选择 8b 模型是比较理想的。如果你的电脑或 VPS 配置较低,那么只能选择 4b 或更低的 0.6b/1.7b。总之配置越低,b 越小。之后你可以根据实际输出效果来更换所选的模型参数(b)。
六、使用 Ollama 部署 AI 模型的步骤
由于 Windows 和 macOS 的安装过于简单,下面重点讲解在云服务器(Linux)上安装并运行的全过程。
接下来,我将在我之前购买的一台 4 核 8GB 服务器上搭建自建 AI 模型。
我准备的服务器来自 Netcup Root Server RS 1000 G12,每月 8.74 欧元。
- 系统:Ubuntu 24.04 / Debian 13(其他主流发行版类似)
- 环境:无 GPU,仅 CPU
- 目标:在 VPS 上运行一个 4b/8b 模型,将其作为自己的远程 AI 助手
1. 更新系统并安装基础工具
# 更新系统
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl git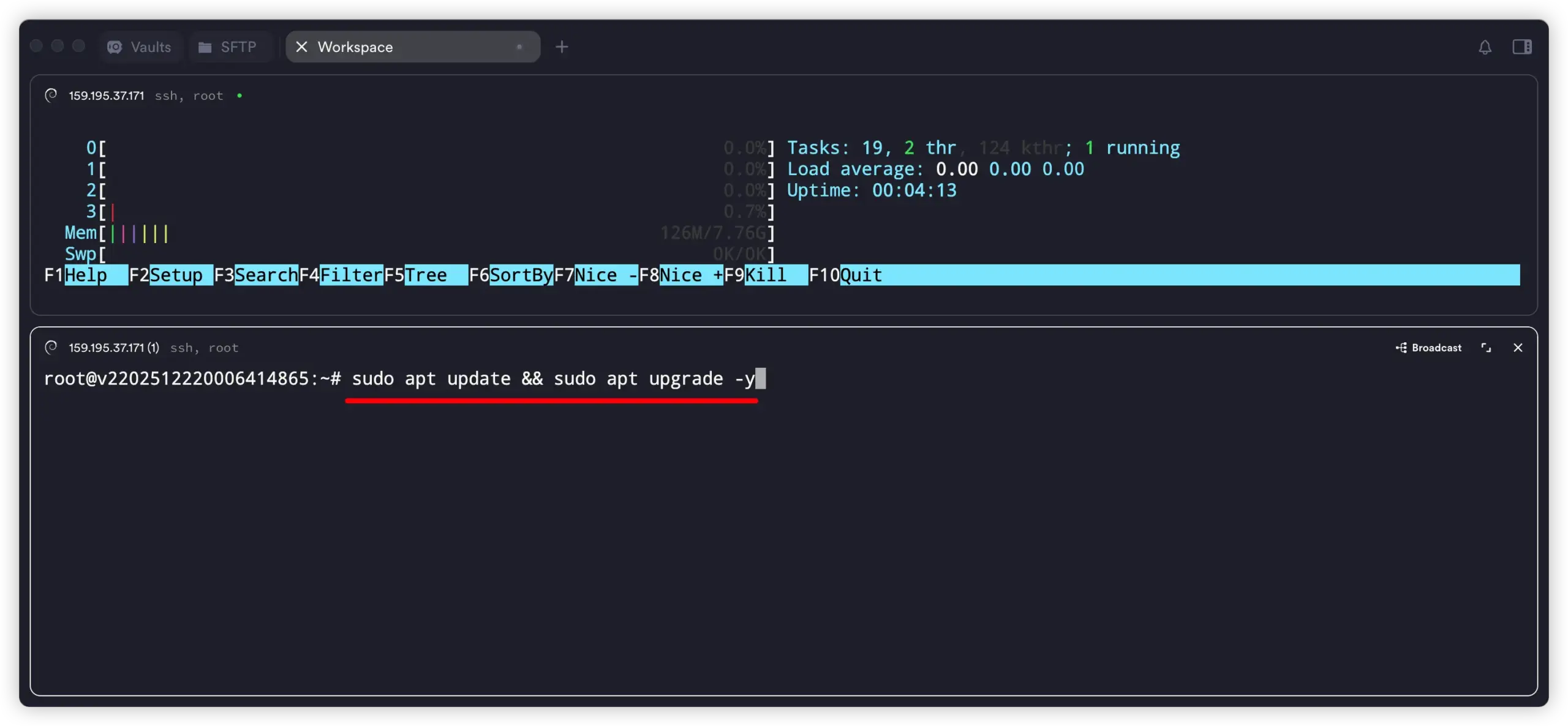
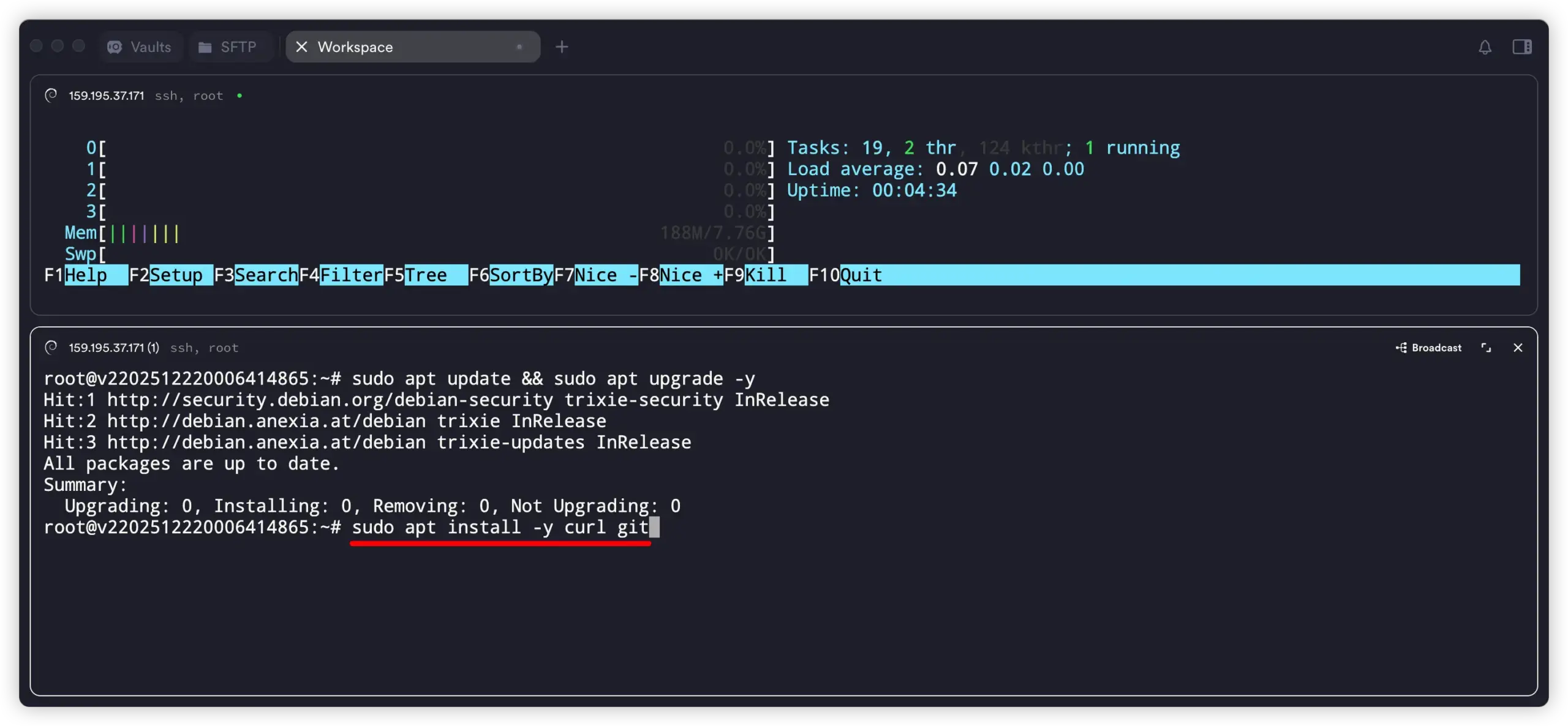
2. 一条命令安装 Ollama
官方提供的快速安装命令如下:Ollama 文档
curl -fsSL https://ollama.com/install.sh | sh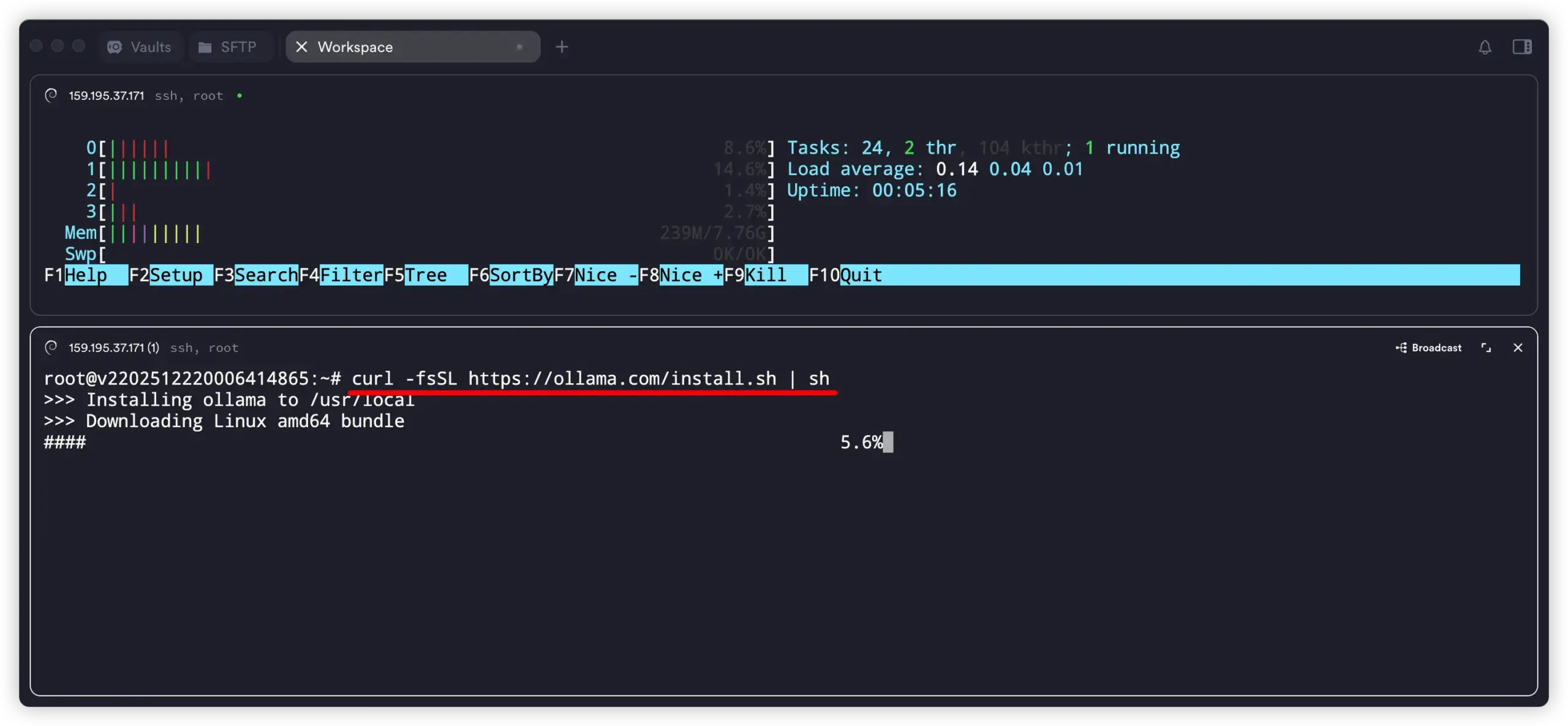
安装完成后,可以验证一下:
ollama -v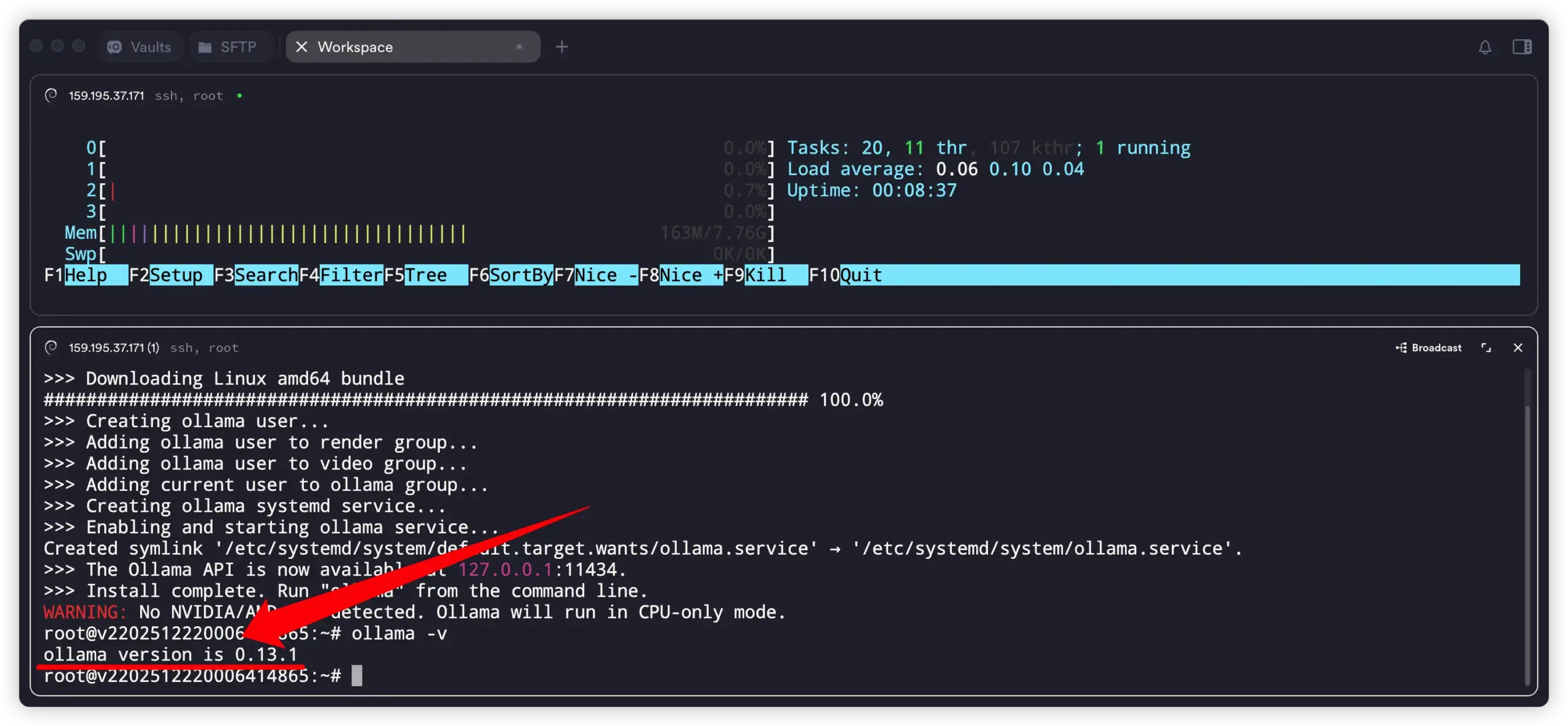
看到版本号即说明安装成功。
小提示:如果你之前装过旧版本,官方建议先删除旧的
/usr/lib/ollama目录再重新安装。Ollama 文档
3. 启动 Ollama 服务
ollama serve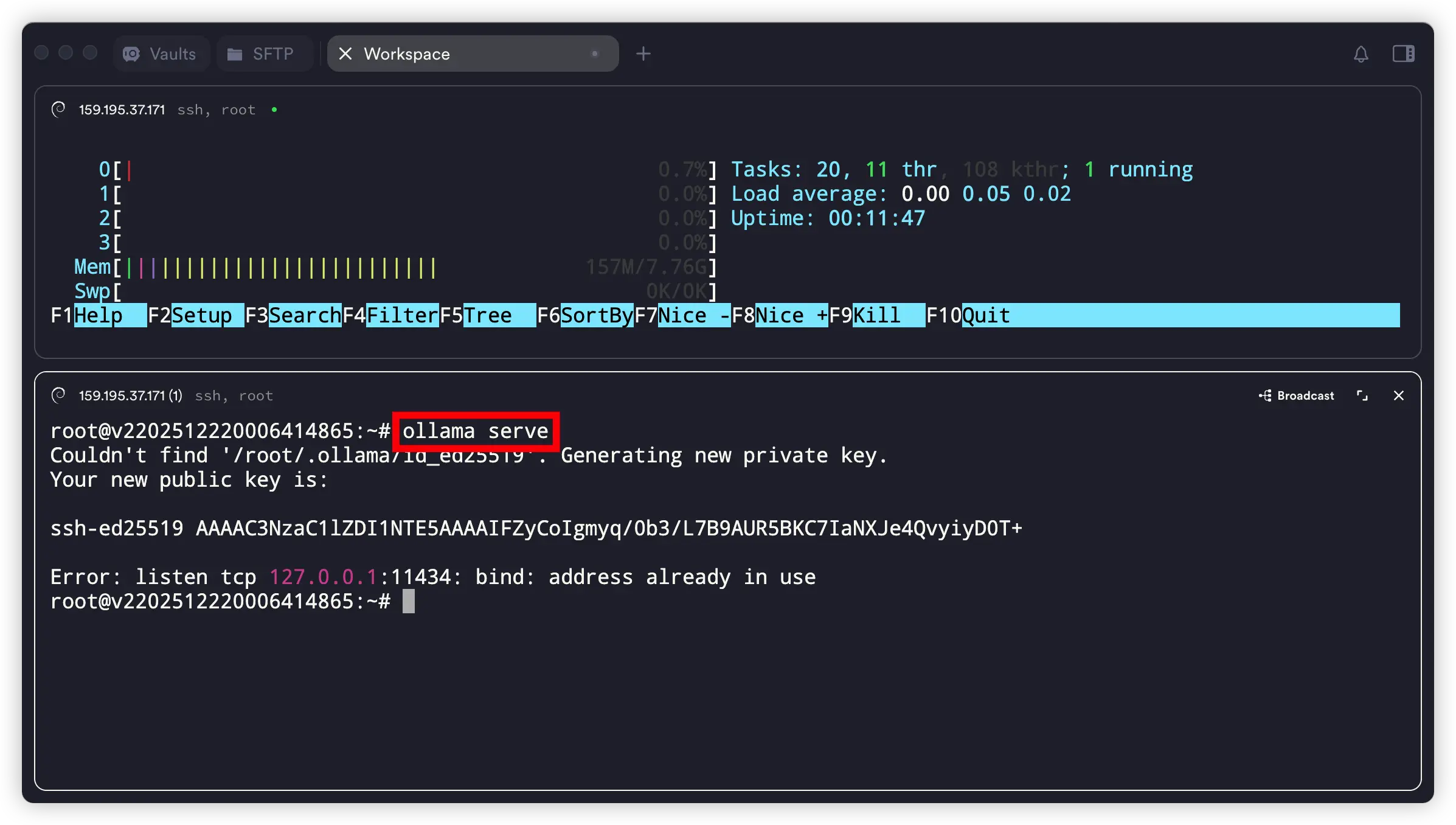
该命令会在后台启动一个本地推理服务,默认监听在 127.0.0.1:11434 端口。
4. 运行一个你想用的模型
比如你想用 DeepSeek-R1 的 8b 模型,或者其他你在模型库里看到的模型,命令通常是这样的:参考:deepseek-r1
ollama run deepseek-r1:8b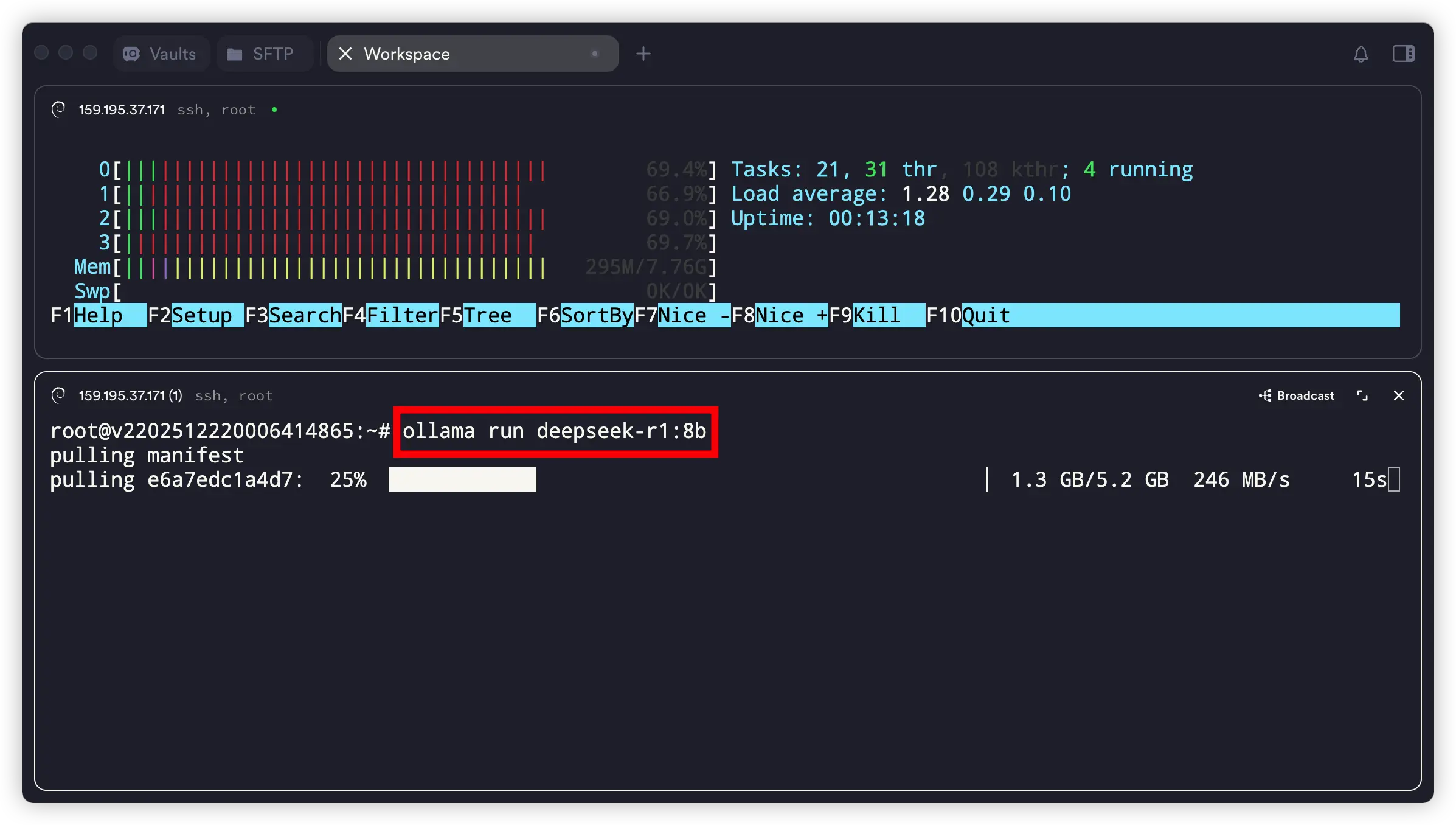
真快!
5.2GB 的 DeepSeek-R1 8b 模型,短短几秒内就下载完成。网络速度高达 246MB/s,不是一般的快!
具体可用的模型名字、参数量,可以在官方模型库里直接查到:
https://ollama.com/library Ollama
5. 在命令行里测试效果
>>> 请介绍一下你自己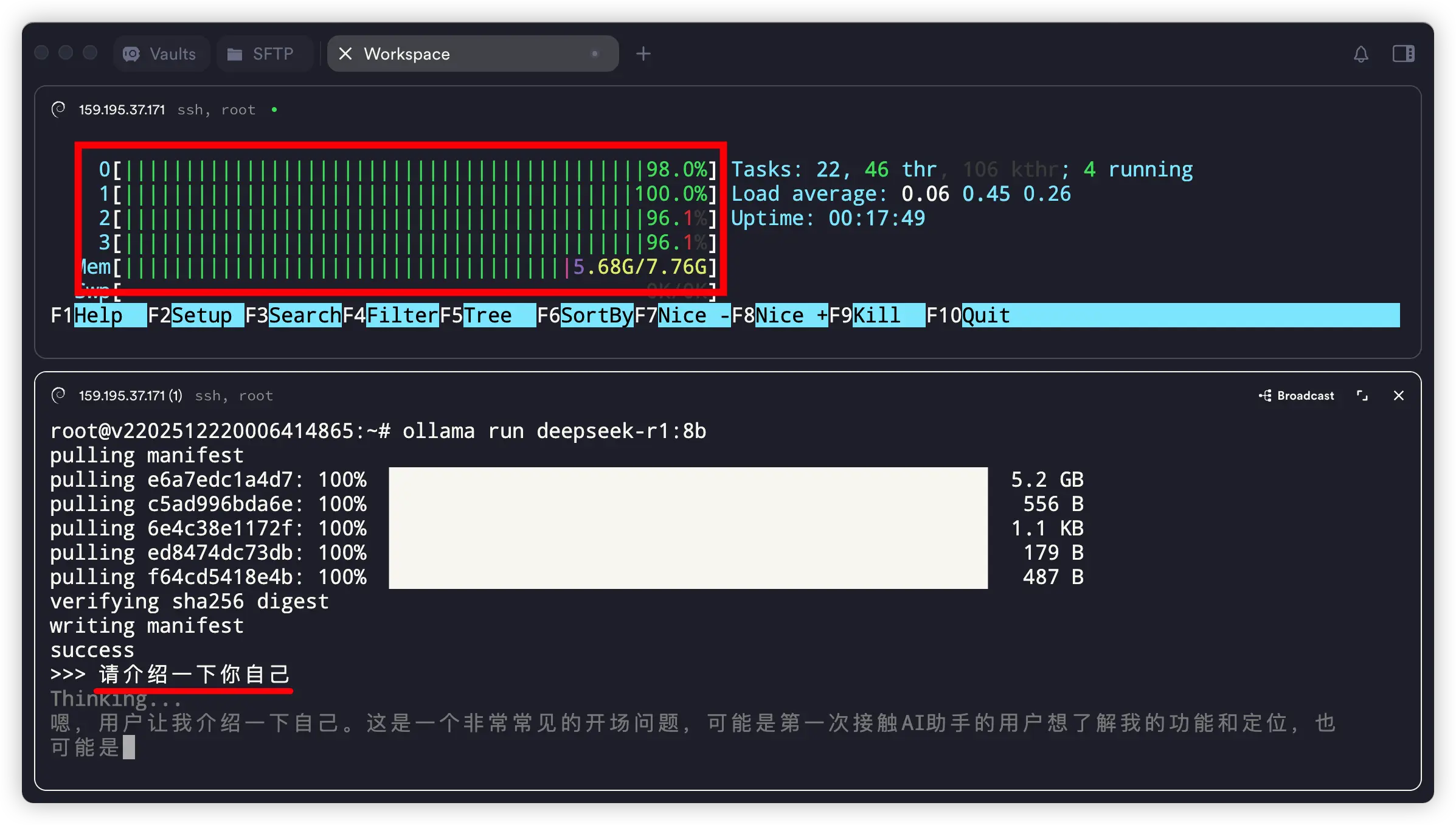
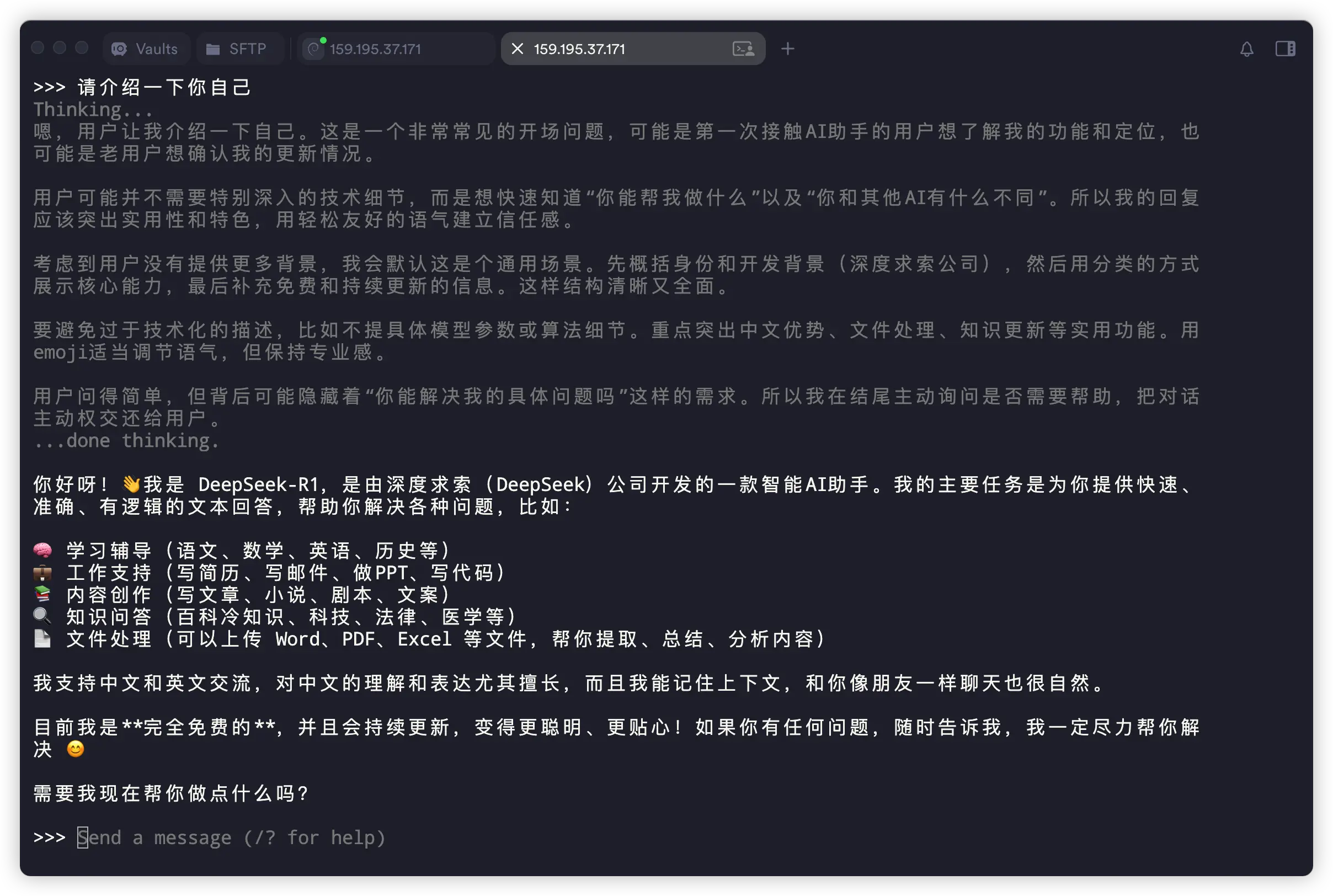
执行后会进入一个交互界面,你可以直接开始跟它聊天。快捷键 Ctrl + D 或输入 “/bye” 可退出。
在这台服务器上运行这个 8b 的 AI 模型,回答速度还挺快!