概述
AI 文章采集器是一款功能强大的 WordPress 插件,支持可视化点选采集目标站文章,并使用主流 AI 工具进行伪原创处理。
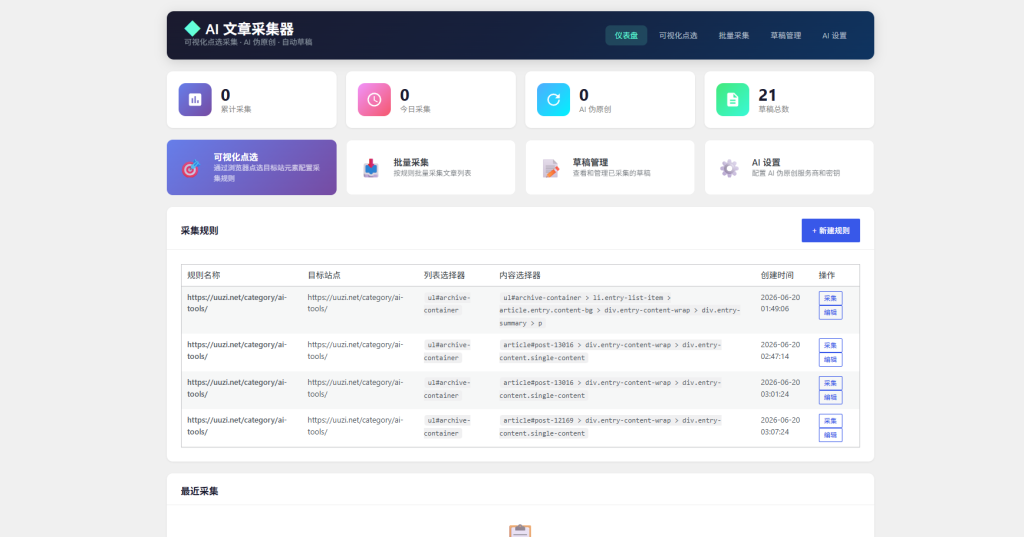
核心功能
1. 可视化点选采集
- 通过 PHP 代理加载目标站页面(绕过跨域限制)
- 鼠标悬停高亮页面元素
- 点击选中元素,自动生成 CSS 选择器
- 支持配置:文章列表、标题、内容、标签、摘要、作者、日期、缩略图
2. 批量采集
- 按规则批量采集文章列表
- 自动去重(已采集过的文章自动跳过)
- 采集后自动保存为草稿
- 支持配置保存状态(草稿/待审核/直接发布)
3. AI 伪原创
支持以下 AI 供应商(持续扩展):
- DeepSeek – 深度求索(推荐,性价比高)
- 小米 MiMo – 小米大模型
- OpenAI – GPT-4o / GPT-4o-mini
- 通义千问 – 阿里云 DashScope
- Kimi (月之暗面) – Moonshot API
- 智谱 GLM – GLM-4 系列
- 百度文心一言 – ERNIE 系列
- Google Gemini – Gemini 1.5/2.0
- 自定义 – 任何 OpenAI 兼容接口
4. 草稿管理
- 查看所有采集的文章
- 状态/标签筛选
- 单篇或批量 AI 伪原创
- 一键跳转到文章编辑器
安装方法
- 将
ai-article-collector文件夹上传到/wp-content/plugins/目录 - 在 WordPress 后台「插件」页面激活「AI 文章采集器」
- 在左侧菜单找到「AI 采集器」开始使用
使用流程
第一步:配置 AI 设置
- 进入「AI 采集器 → AI 设置」
- 选择 AI 供应商
- 填入 API Key
- 测试连接
- 保存设置
第二步:创建采集规则
- 进入「AI 采集器 → 可视化点选」
- 输入目标站文章列表页 URL
- 点击「加载页面」
- 开启「点选模式」
- 在页面预览中点击元素,自动填入选择器
- 测试采集效果
- 保存规则
第三步:批量采集
- 进入「AI 采集器 → 批量采集」
- 选择采集规则
- 设置采集数量
- 点击「开始采集」
- 查看采集结果
第四步:AI 伪原创
- 进入「AI 采集器 → 草稿管理」
- 勾选需要处理的文章
- 点击「批量 AI 伪原创」
- 或单篇点击「AI 伪原创」
兼容性
- WordPress 4.7+(含 WordPress 7.0)
- PHP 5.6+
- 需要启用 cURL 或 allow_url_fopen
文件结构
ai-article-collector/
├── ai-article-collector.php # 主插件文件
├── uninstall.php # 卸载清理脚本
├── includes/
│ ├── class-html-parser.php # HTML 解析工具(DOMDocument + XPath)
│ ├── class-selector-engine.php # 可视化选择器引擎(页面代理 + 字段提取)
│ ├── class-collector.php # 采集引擎(批量采集 + 草稿保存)
│ ├── class-ai-service.php # AI 伪原创服务(多供应商)
│ ├── class-settings.php # 设置管理
│ └── class-draft-manager.php # 草稿管理
├── admin/views/
│ ├── header.php # 后台公共头部
│ ├── dashboard-page.php # 仪表盘
│ ├── selector-page.php # 可视化点选页
│ ├── collector-page.php # 批量采集页
│ ├── drafts-page.php # 草稿管理页
│ └── settings-page.php # AI 设置页
├── assets/
│ ├── css/
│ │ ├── admin.css # 后台通用样式
│ │ └── selector.css # 选择器/采集器样式
│ └── js/
│ ├── admin.js # 后台通用脚本
│ ├── selector.js # 可视化点选引擎
│ └── collector.js # 采集/草稿交互
└── languages/
└── ai-article-collector-zh_CN.po # (待编译)数据库表
插件激活时会自动创建 wp_aac_collection_logs 表,记录采集历史。
技术要点
- 零依赖:HTML 解析使用 PHP 内置 DOMDocument,无需安装 Simple HTML DOM Parser
- 跨域解决:通过 PHP 代理加载目标页面,在前端 iframe 中渲染
- CSS 选择器生成:JavaScript 自动分析 DOM 结构,生成 tag.class 格式的选择器
- AI 统一接口:所有 OpenAI 兼容供应商共用同一套调用逻辑,Gemini 独立适配
- 安全机制:所有 AJAX 请求使用 WordPress nonce 验证,数据通过 sanitize 函数清理
AI Article Collector — 插件介绍与操作教程
版本:1.8.0
适用 WordPress:4.7 ~ 7.0+
PHP 版本:5.6+
一、插件简介
AI Article Collector(AI 文章采集器)是一款 WordPress 插件,帮助你从任意网站快速采集文章,并使用主流 AI 工具进行伪原创处理。
核心特性
| 特性 | 说明 |
|---|---|
| 可视化点选 | 鼠标点击页面元素即可生成采集规则,无需手写 CSS 选择器 |
| 8 步向导 | 从设置目标站到预览保存,分步操作,每步可回退 |
| 文章详情页加载 | 支持在预览区直接点击链接跳转到文章详情页 |
| 批量采集 | 逐篇采集,实时显示进度和结果 |
| 图片本地化 | 自动下载文章图片到 WordPress 媒体库,不再引用源站链接 |
| 9 种 AI 供应商 | DeepSeek、小米 MiMo、OpenAI、通义千问、Kimi、智谱 GLM、百度文心、Google Gemini、自定义 |
| 容错匹配 | 选择器自动降级匹配(去 class → 去 ID → 全文搜索),适配不同文章结构 |
| 草稿管理 | 采集文章集中管理,支持单篇/批量 AI 伪原创 |
二、安装方法
- 将
ai-article-collector文件夹上传到 WordPress 的/wp-content/plugins/目录 - 登录 WordPress 后台,进入「插件」页面
- 找到「AI Article Collector」,点击「启用」
- 启用后,左侧菜单出现「AI 采集器」入口
卸载说明:停用并删除插件时,
uninstall.php会自动清理采集日志表和插件配置,不会删除已采集的文章。
三、功能模块一览
启用插件后,左侧菜单「AI 采集器」下有 5 个子菜单:
| 菜单 | 功能 |
|---|---|
| 仪表盘 | 总览采集数据、最近活动 |
| 可视化点选 | 8 步向导创建采集规则 |
| 批量采集 | 选择规则批量采集文章 |
| 草稿管理 | 管理已采集文章,AI 伪原创 |
| AI 设置 | 配置 AI 供应商、采集选项 |
四、操作教程
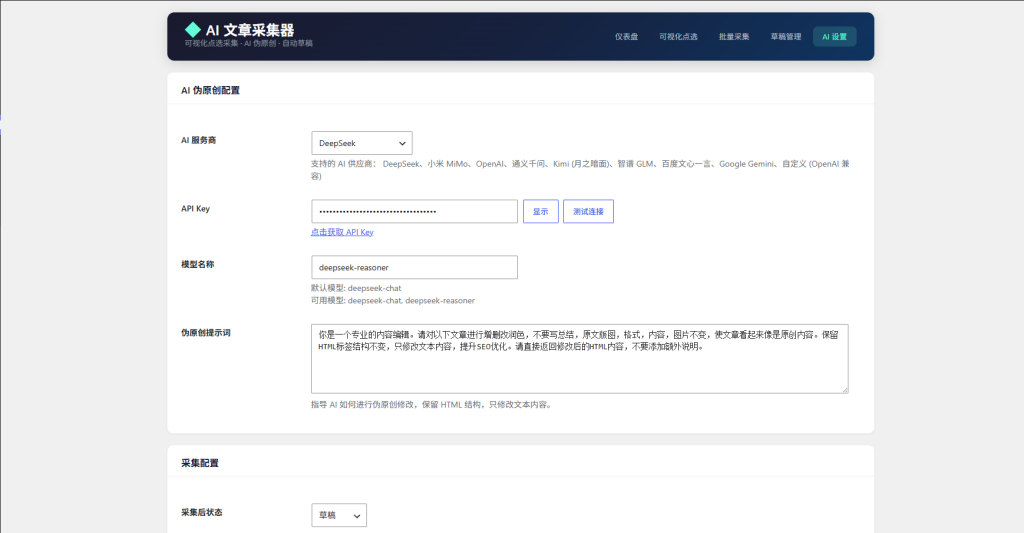
4.1 配置 AI 设置(建议先做)
进入「AI 采集器 → AI 设置」,完成以下配置:
AI 伪原创配置
| 配置项 | 说明 |
|---|---|
| AI 服务商 | 选择你要使用的 AI 供应商(推荐 DeepSeek,性价比高) |
| API Key | 填入对应供应商的 API Key,点击「显示」可查看明文 |
| 测试连接 | 点击「测试连接」按钮验证 Key 是否有效 |
| 模型名称 | 留空使用默认模型,也可手动指定 |
| API Endpoint | 仅「自定义」模式需要填写,必须兼容 OpenAI 格式 |
| 伪原创提示词 | 指导 AI 如何修改文章,保留 HTML 结构,只改文字内容 |
各供应商 API Key 获取地址:
- DeepSeek:https://platform.deepseek.com/
- 小米 MiMo:https://mimo.xiaomi.com/
- OpenAI:https://platform.openai.com/api-keys
- 通义千问:https://dashscope.console.aliyun.com/
- Kimi:https://platform.moonshot.cn/
- 智谱 GLM:https://open.bigmodel.cn/
- 百度文心:https://console.bce.baidu.com/qianfan/
- Google Gemini:https://aistudio.google.com/apikey
采集配置
| 配置项 | 说明 |
|---|---|
| 采集后状态 | 草稿 / 待审核 / 直接发布 |
| 采集后自动伪原创 | 勾选后每采集完一篇自动调用 AI 伪原创 |
| 移除原文链接 | 清理文章内容中的外链 |
| 移除原文图片 | 完全移除文章中的图片标签 |
| 图片本地化 | 下载文章图片到媒体库,替换为本地链接(默认开启) |
| 请求超时 | 单篇文章采集的超时时间(秒),建议 30~60 |
| User-Agent | 请求目标站时使用的 UA,留空使用默认值 |
配置完成后点击页面底部「保存设置」。
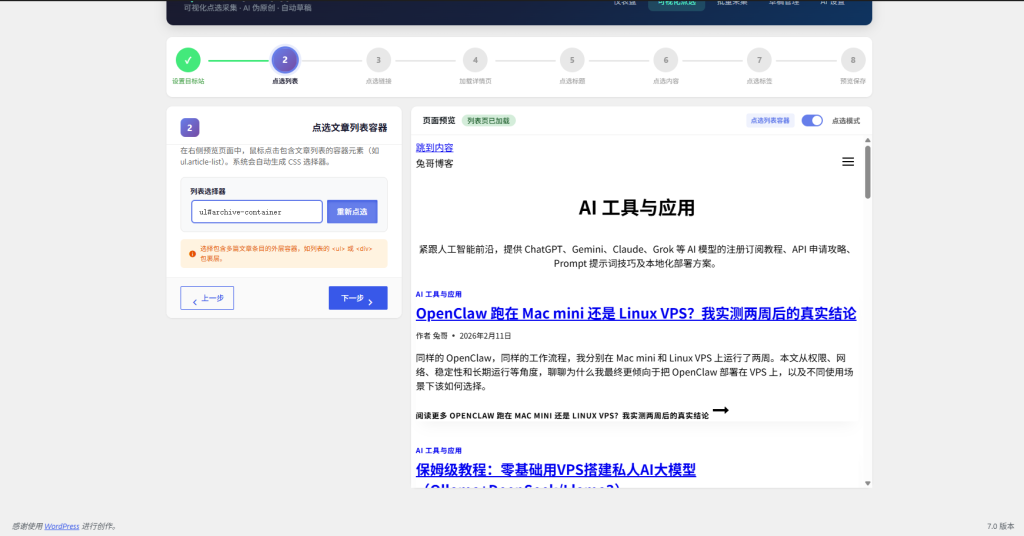
4.2 创建采集规则(可视化点选 8 步向导)
进入「AI 采集器 → 可视化点选」,界面为左右双栏布局:左侧是步骤表单,右侧是页面预览区。
第 1 步:设置目标站
- 在左侧输入规则名称(如「科技博客采集」)
- 输入目标站文章列表页 URL(如
https://example.com/blog/) - 点击「加载页面」
- 右侧预览区会加载目标站列表页
- 确认页面加载成功后,点击「下一步」
目标站 URL 必须是文章列表页,不是单篇文章页。
第 2 步:点选列表
- 点击左侧「开启点选」按钮
- 在右侧预览区中,鼠标悬停会高亮元素
- 点击包含文章列表的容器元素(通常是
<ul>或<div>包裹的列表区域) - 左侧「列表选择器」自动填入生成的 CSS 选择器
- 确认选择器正确后,点击「下一步」
如果选错了元素,再次点击正确的元素即可覆盖。
第 3 步:点选链接
- 左侧显示「链接选择器」输入框,默认值为
a - 点击「开启点选」按钮
- 在右侧预览区中点击列表中的某个文章链接
- 选择器自动更新(如
article h2 a) - 系统会自动提取列表中所有匹配的文章链接并显示
- 确认链接列表正确后,点击「下一步」
链接选择器可手动编辑修改。如果自动提取的链接不准确,可以手动调整。
第 4 步:加载文章详情页
这一步是为了加载单篇文章详情页,以便后续点选标题和内容。
方式 A(推荐):在预览区直接点击文章链接
- 进入此步骤后,预览区自动切换为「导航模式」
- 鼠标悬停在文章链接上会显示橙色高亮和「点击加载此页面」提示
- 点击任意文章标题链接,系统自动获取该 URL 并加载到预览区
- URL 会自动填入左侧输入框
方式 B(兜底):手动输入文章详情页 URL
- 在左侧「文章详情页 URL」输入框中粘贴文章 URL
- 点击「加载」按钮
确认右侧预览区显示的是文章详情页(而非列表页)后,点击「下一步」。
如果点击加载后仍显示列表页,请使用方式 B 手动输入文章详情页 URL。
第 5 步:点选标题
- 点击「开启点选」按钮
- 在右侧预览区中点击文章标题元素(通常是
<h1>或<h2>) - 左侧「标题选择器」自动填入
- 预览区下方会显示提取到的标题文本
- 确认正确后点击「下一步」
第 6 步:点选内容
- 点击「开启点选」按钮
- 在右侧预览区中点击文章正文内容容器(如
div.entry-content、div.article-body等) - 左侧「内容选择器」自动填入
- 预览区下方显示提取到的内容预览
- 确认正确后点击「下一步」
选择内容容器时要选包含完整正文的父级元素,不要只选某一段文字。
第 7 步:点选标签
- 点击「开启点选」按钮
- 在右侧预览区中点击文章标签区域(如
div.tags、ul.post-tags等) - 如果文章没有标签或不需要采集标签,可直接跳过
- 点击「下一步」
第 8 步:预览保存
- 左侧显示所有已配置的选择器汇总
- 点击「测试采集」按钮,系统会使用当前规则采集一篇文章进行测试
- 查看采集结果(标题、内容、标签、来源 URL)
- 确认无误后,输入规则名称
- 点击「保存规则」
保存规则后,可以在「批量采集」页面使用该规则。
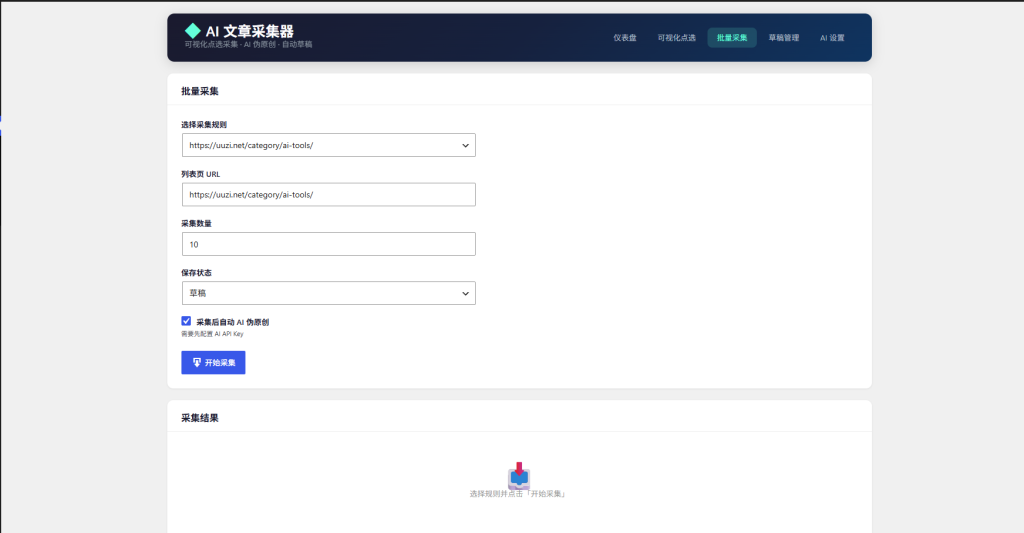
4.3 批量采集文章
进入「AI 采集器 → 批量采集」:
- 选择采集规则:从下拉菜单选择已保存的规则
- 输入采集 URL:默认使用规则中保存的列表页 URL,也可以临时修改
- 设置采集数量:限制本次采集的文章数量(如 10 篇)
- AI 自动伪原创:勾选后每篇采集完成自动调用 AI 处理
- 点击「开始采集」
采集过程中:
- 系统先获取文章链接列表(快速返回)
- 然后逐篇采集,每篇实时显示状态(等待中 → 采集中 → 成功/失败)
- 进度条显示整体进度
- 采集成功的文章显示标题、摘要、来源链接
- 采集失败的文章显示具体错误原因
- 可点击「编辑」跳转到 WordPress 文章编辑器
已采集过的文章会自动跳过,不会重复采集。
4.4 草稿管理与 AI 伪原创
进入「AI 采集器 → 草稿管理」:
- 查看所有已采集的文章列表
- 按状态筛选(草稿 / 待审核 / 已发布)
- 按标签筛选
- 点击文章标题可直接编辑
- 点击「编辑」按钮跳转到 WordPress 文章编辑器
AI 伪原创操作
单篇伪原创:
- 在文章列表中找到目标文章
- 点击「AI 伪原创」按钮
- 等待 AI 处理完成(页面会显示处理状态)
- 处理完成后文章内容会被 AI 重写
批量伪原创:
- 勾选需要处理的多篇文章
- 点击页面顶部「批量 AI 伪原创」按钮
- 系统逐篇调用 AI 处理
- 实时显示每篇的处理状态
AI 伪原创会保留文章 HTML 结构(标题、段落、图片标签等),只修改文字内容。
4.5 仪表盘
进入「AI 采集器 → 仪表盘」:
- 查看采集总数、伪原创数、草稿数等统计信息
- 查看最近采集活动
- 快捷入口:可视化点选、批量采集、草稿管理、AI 设置
五、常见问题
Q1:加载目标站后无法点选?
- 检查浏览器控制台是否有 JS 报错
- 确保浏览器支持 iframe sandbox
- 尝试刷新页面后重新操作
Q2:点选的标题/内容在批量采集时采集不到?
这通常是因为选择器中包含了文章特定的动态 ID(如 post-13016)。插件已内置容错机制(自动跳过动态 ID、降级匹配),如果仍有问题:
- 在「可视化点选」中重新点选元素,选择不含数字 ID 的容器
- 优先选择使用 class 标识的元素(如
div.entry-content)
Q3:采集内容为空?
- 确认第 4 步加载的是文章详情页而非列表页
- 确认内容选择器选中的是包含完整正文的容器
- 检查目标站是否有反爬机制(可在设置中调整 User-Agent)
- 适当增大「请求超时」时间
Q4:图片显示不了?
- 确保「图片本地化」已开启(设置 → 采集配置)
- 确保服务器有写入权限(
wp-content/uploads/可写) - 检查目标站图片是否可正常访问
Q5:AI 伪原创失败?
- 检查 AI 设置中的 API Key 是否正确
- 点击「测试连接」验证
- 检查当前模型是否可用
- 查看错误提示信息
- 部分供应商需要账户充值后才能调用
Q6:采集速度慢?
- 降低单次采集数量
- 关闭「采集后自动伪原创」,改为采集完成后再批量处理
- 增大请求超时设置
六、技术架构简述
| 模块 | 技术方案 |
|---|---|
| HTML 解析 | PHP 内置 DOMDocument + DOMXPath,零外部依赖 |
| 跨域加载 | PHP wp_remote_get 代理获取目标站 HTML |
| 可视化点选 | iframe 渲染目标页 + 注入 JS 脚本 + postMessage 回传选择器 |
| CSS → XPath | 自定义转换器,支持 > 子选择器、后代选择器、#id、.class、[attr=val]、:first-child、:last-child |
| 容错查询 | 4 级降级:去多余 class → 去 ID → 去所有 class → 最后 token 全文搜索 |
| 动态 ID 跳过 | JS 生成选择器时跳过含数字的 ID(如 post-13016),只保留纯字母语义 ID |
| 图片本地化 | DOMDocument 遍历 <img> → download_url + media_handle_sideload 下载到媒体库 |
| AI 调用 | OpenAI 兼容格式统一调用(8 家共用),Gemini 独立适配 |
| 安全机制 | 所有 AJAX 请求使用 WordPress nonce 验证,数据通过 sanitize 函数清理 |
七、文件结构
ai-article-collector/
├── ai-article-collector.php # 主入口(插件头、菜单注册、AJAX 钩子)
├── uninstall.php # 卸载清理脚本
├── GUIDE.md # 本文档
├── README.md # 项目说明
├── includes/
│ ├── class-html-parser.php # HTML 解析(DOMDocument + CSS→XPath + 容错查询)
│ ├── class-selector-engine.php # 页面代理 + 字段提取 + 链接提取
│ ├── class-collector.php # 采集引擎(批量/单篇/草稿保存/图片本地化)
│ ├── class-ai-service.php # AI 伪原创(9 种供应商)
│ ├── class-settings.php # 设置 + 规则管理
│ └── class-draft-manager.php # 草稿列表查询
├── admin/views/
│ ├── header.php # 后台公共头部
│ ├── dashboard-page.php # 仪表盘
│ ├── selector-page.php # 可视化点选页(8 步向导)
│ ├── collector-page.php # 批量采集页
│ ├── drafts-page.php # 草稿管理页
│ └── settings-page.php # AI 设置页
├── assets/
│ ├── css/
│ │ ├── admin.css # 后台通用样式
│ │ └── selector.css # 点选/采集器样式
│ └── js/
│ ├── admin.js # 通用工具(AJAX 封装、提示等)
│ ├── selector.js # 可视化点选引擎(iframe + postMessage + 导航模式)
│ └── collector.js # 采集/草稿交互(逐篇串行采集)
└── languages/
└── (待编译)八、版本更新日志
| 版本 | 更新内容 |
|---|---|
| 1.8.0 | 新增图片本地化功能(下载文章图片到媒体库) |
| 1.7.0 | 修复选择器含动态 ID 导致批量采集标题错误 |
| 1.6.0 | 修复 css_to_xpath 不支持 > 子选择器导致采集内容为空 |
| 1.5.0 | 新增 iframe 内点击链接导航模式,手动 URL 输入框默认显示 |
| 1.4.0 | 新增第 4 步「加载文章详情页」,支持手动输入 URL 兜底 |
| 1.3.0 | 改为逐篇串行采集模式,修复采集结果为空问题 |
| 1.2.0 | 重构为左右双栏 8 步向导布局 |
| 1.0.0 | 初始版本:可视化点选 + 批量采集 + AI 伪原创 |